lutpa statute of limitationszulu's family crossword clue
Optional parameters may be passed, please check test/main_online_sf_ksl.cpp. Scientific reports, 10(1), 1-14. vis-www.cs.umass.edu/motionsegmentation/website_cvpr18/index.html, The Best of Both Worlds: Combining CNNs and Geometric Constraints for Hierarchical Motion Segmentation, Running code without "objectness" knowledge, The Best of Both Worlds: Combining CNNs andGeometric Constraints for Hierarchical Motion Segmentation (CVPR 2018). Robust motion detection/segmentation using OpenCV. In addition an approach to estimate the camera's rotation and translation diretion is provided. Add a  simpleSolver(savePath,startstep=1,endstep=7,fileScale=None,getCompoundTimeList=None,compoundSchemeList=None,fftLagrangian=True,pngFileFormat=None,period=None,maskImg=True,anchor=None,peroid=None,bgrid=4.,finalShape=None,fourierTerms=4,twoD=False). If you use this code in a scientific publication, please cite the following paper: Online 3DKSL performs motion segmentation of articulated rigid bodies from RGB-D data in a frame-by-frame basis. You signed in with another tab or window. Code for unsupervised bottom-up video motion segmentation. A demo version of the code can be run in MATALB by simply executing. This code accompanies the paper: Self-supervised Video Object Segmentation by Motion Grouping. Please run run_davis.py and run_youtube.py. ECCV 2022. If you find this work useful in your research, please cite: Video Segmentation using low-level vision based unsupervised methods. However, please download DAVIS-17 to fit the code. Our method can also perform video editing (aka part-swaps). Deviations from the main paper are the following: This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository. We demonstrate in simulated as well as in real experiments that our method is very effective in reducing the errors in the pairwise motion segmentation and can cope with large number of mismatches. lucid dreaming data SimpleElastix: SimpleElastix v0.9.0 (Version v0.9.0-SimpleElastix). You signed in with another tab or window. Precomputed input data (flow and object proposal masks) as well as final segmentation masks computed using this code can be downloaded under the following links: Commit abcdef follows the implementation of the hierarchical-motion-segmentation paper. You signed in with another tab or window. In that case no precomputed results from an object proposal algorithm are required. This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository. This project is licensed under the MIT License - see the LICENSE file for details. Some helper functions are available in tools. Deep Motion Segmentation (specifically in Autonomous Driving application). To associate your repository with the An executable is provided as an example, which will be located in the bin directory. For swaping either target or source segmentation mask can be used (specify --use_source_segmentation for using source segmentation mask). We use the dataset version with 6fps rather than 30fps. ParticleSfM: Exploiting Dense Point Trajectories for Localizing Moving Cameras in the Wild. Use --resume_path {} if you are fine-tuning. C. Yang, H. Lamdouar, E. Lu, A. Zisserman, W. Xie. If you find MATNet useful for your research, please consider citing the following papers: This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository. This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository. The probabilities of event clusters during the iterations: IWE (Image of Warpped Events) after 3 iterations: The scenario with only 1 cluster but the parameter of cluster number was set to 2: This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository. This repository use the same dataset format as First Order Motion Model so you can use the same data as in 1). [CVPR 2017] Video motion segmentation and tracking. https://www.imperial.ac.uk/personal-robotics/software/, http://pointclouds.org/downloads/linux.html, https://docs.opencv.org/trunk/d7/d9f/tutorial_linux_install.html, http://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html, http://eigen.tuxfamily.org/index.php?title=Main_Page#Download, https://github.com/ImperialCollegeLondon/3DKSL.git, cmake .. -DCMAKE_BUILD_TYPE=Release && make. This repository contains the source code for the paper Motion Supervised co-part Segmentation by Aliaksandr Siarohin*, Subhankar Roy*, Stphane Lathuilire, Sergey Tulyakov, Elisa Ricci and Nicu Sebe. The rest has to be converted to DAVIS format. Add a description, image, and links to the
simpleSolver(savePath,startstep=1,endstep=7,fileScale=None,getCompoundTimeList=None,compoundSchemeList=None,fftLagrangian=True,pngFileFormat=None,period=None,maskImg=True,anchor=None,peroid=None,bgrid=4.,finalShape=None,fourierTerms=4,twoD=False). If you use this code in a scientific publication, please cite the following paper: Online 3DKSL performs motion segmentation of articulated rigid bodies from RGB-D data in a frame-by-frame basis. You signed in with another tab or window. Code for unsupervised bottom-up video motion segmentation. A demo version of the code can be run in MATALB by simply executing. This code accompanies the paper: Self-supervised Video Object Segmentation by Motion Grouping. Please run run_davis.py and run_youtube.py. ECCV 2022. If you find this work useful in your research, please cite: Video Segmentation using low-level vision based unsupervised methods. However, please download DAVIS-17 to fit the code. Our method can also perform video editing (aka part-swaps). Deviations from the main paper are the following: This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository. We demonstrate in simulated as well as in real experiments that our method is very effective in reducing the errors in the pairwise motion segmentation and can cope with large number of mismatches. lucid dreaming data SimpleElastix: SimpleElastix v0.9.0 (Version v0.9.0-SimpleElastix). You signed in with another tab or window. Precomputed input data (flow and object proposal masks) as well as final segmentation masks computed using this code can be downloaded under the following links: Commit abcdef follows the implementation of the hierarchical-motion-segmentation paper. You signed in with another tab or window. In that case no precomputed results from an object proposal algorithm are required. This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository. This project is licensed under the MIT License - see the LICENSE file for details. Some helper functions are available in tools. Deep Motion Segmentation (specifically in Autonomous Driving application). To associate your repository with the An executable is provided as an example, which will be located in the bin directory. For swaping either target or source segmentation mask can be used (specify --use_source_segmentation for using source segmentation mask). We use the dataset version with 6fps rather than 30fps. ParticleSfM: Exploiting Dense Point Trajectories for Localizing Moving Cameras in the Wild. Use --resume_path {} if you are fine-tuning. C. Yang, H. Lamdouar, E. Lu, A. Zisserman, W. Xie. If you find MATNet useful for your research, please consider citing the following papers: This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository. This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository. The probabilities of event clusters during the iterations: IWE (Image of Warpped Events) after 3 iterations: The scenario with only 1 cluster but the parameter of cluster number was set to 2: This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository. This repository use the same dataset format as First Order Motion Model so you can use the same data as in 1). [CVPR 2017] Video motion segmentation and tracking. https://www.imperial.ac.uk/personal-robotics/software/, http://pointclouds.org/downloads/linux.html, https://docs.opencv.org/trunk/d7/d9f/tutorial_linux_install.html, http://docs.nvidia.com/cuda/cuda-installation-guide-linux/index.html, http://eigen.tuxfamily.org/index.php?title=Main_Page#Download, https://github.com/ImperialCollegeLondon/3DKSL.git, cmake .. -DCMAKE_BUILD_TYPE=Release && make. This repository contains the source code for the paper Motion Supervised co-part Segmentation by Aliaksandr Siarohin*, Subhankar Roy*, Stphane Lathuilire, Sergey Tulyakov, Elisa Ricci and Nicu Sebe. The rest has to be converted to DAVIS format. Add a description, image, and links to the  You signed in with another tab or window. Stay informed on the latest trending ML papers with code, research developments, libraries, methods, and datasets. https://github.com/AliaksandrSiarohin/video-preprocessing, For computing the MAE download eval_images.tar.gz from. ./example_online_sf_ksl path-to-RGB-dir path-toDepth-dir.
You signed in with another tab or window. Stay informed on the latest trending ML papers with code, research developments, libraries, methods, and datasets. https://github.com/AliaksandrSiarohin/video-preprocessing, For computing the MAE download eval_images.tar.gz from. ./example_online_sf_ksl path-to-RGB-dir path-toDepth-dir. ![]() You signed in with another tab or window. Other minor Python modules can be installed by running, git clone --recursive https://github.com/tfzhou/MATNet.git. ECCV 2022. The pre-trained model can be downloaded from Google Drive. [2020/03/04] Update results for DAVIS-17 validation set! The codes are borrowed from https://github.com/sniklaus/pytorch-pwc. Helper functions are available in tools. The code generates motion segmentation masks segmenting multiple independently moving objects. Our approach is inspired by the success of averaging methods. Please follow the instruction from https://github.com/AliaksandrSiarohin/video-preprocessing. First, motion segmentation is performed on image pairs independently. We prepare a special demo for the google-colab, see: part_swap.ipynb. I am mainly focusing in the paper collection on: If you want to add your paper you can create an issue.
You signed in with another tab or window. Other minor Python modules can be installed by running, git clone --recursive https://github.com/tfzhou/MATNet.git. ECCV 2022. The pre-trained model can be downloaded from Google Drive. [2020/03/04] Update results for DAVIS-17 validation set! The codes are borrowed from https://github.com/sniklaus/pytorch-pwc. Helper functions are available in tools. The code generates motion segmentation masks segmenting multiple independently moving objects. Our approach is inspired by the success of averaging methods. Please follow the instruction from https://github.com/AliaksandrSiarohin/video-preprocessing. First, motion segmentation is performed on image pairs independently. We prepare a special demo for the google-colab, see: part_swap.ipynb. I am mainly focusing in the paper collection on: If you want to add your paper you can create an issue.  For DAVIS: use the official evaluation code: Generate optical flow from your dataset using raft/inference.py, Edit setup_dataset in config.py to include your dataset, and add this to the choices in parser.add_argument('--dataset') in train.py and eval.py. Add a description, image, and links to the Checkpoints can be found under following links: yandex-disk and google-drive. uNLC is a reimplementation of the NLC algorithm by Faktor and Irani, BMVC 2014, that removes the trained edge detector and makes numerous other modifications and simplifications. 2 Bradley Lowekamp, ., gabehart, ., Daniel Blezek, ., Luis Ibanez, ., Matt McCormick, ., Dave Chen, ., Brad King, . topic page so that developers can more easily learn about it. flow of all three datasets (FBMS, camouflaged animals and complex background): object proposal masks of all three datasets (FBMS, camouflaged animals and complex background): final motion segmentation masks used for evaluation. The code is documented and designed to be extended. It will automatically choose the subset of DAVIS-16 for training. Our method is a self-supervised deep learning method for co-part segmentation. Github repository for our CVPR 17 paper is here. Follow the training and inference instructions above with your own --dataset argument. Please follow the setup section to install cupy. Repository accompanying the paper: Self-supervised Video Object Segmentation by Motion Grouping. set the folder path to be used where the generated and required files will be are. This allignment can only be used along with --supervised option. I have provided the pytorch codes to generate HED results for the two datasets (see 3rdparty/pytorch-hed). If you use this code in a scientific publication, please cite the following paper: An executable is provided as an example, which will be located in the bin directory. Each of them as well can be categorized into pixel-wise or instance-wise segmentation. Add a description, image, and links to the and data/run_youtube.m. MPNet: Use of Optical flow encoded as RGB for learning Motion Segmentation. people.eecs.berkeley.edu/~pathak/unsupervised_video/, CVPR 2017 paper on Unsupervised Learning using unlabeled videos, Install kernel temporal segmentation code. This is non-official code for paper https://arxiv.org/abs/1904.01293 by Timo Stoffregen, Guillermo Gallego, Tom Drummond, Lindsay Kleeman, Davide Scaramuzza. You signed in with another tab or window. In Proceedings of 28th European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning (ESANN), Bruges, Belgium, April 2020. Motion Segmentation using Frequency Domain Transformer Networks. mediapipe inference mapillary github bugreport upload tools Robust motion detection/segmentation using OpenCV. For fully-supervised add --supervised option. Set the final uniform bspline grid shape (NUMBER OF CONTROL POINTS IN x,NUMBER OF CONTROL POINTS IN y,NUMBER OF CONTROL POINTS IN z,NUMBER FOURIER COEFFICIENTS PER CONTROL POINT, NUMBER OF DIMENSIONS), if None, it will default to the shape in t0 -> t1 registration. The training and testing experiments are conducted using PyTorch 1.0.1 with a single GeForce RTX 2080Ti GPU with 11GB Memory. motion-segmentation Charig Yang, Hala Lamdouar, Erika Lu, Andrew Zisserman, Weidi Xie. [Arxiv] [TIP]. Offline 3DKSL performs motion segmentation of articulated rigid bodies from a batch of RGB-D data sequence. A path to the directory containing the RGB data sequence must be provided, as well as a path to the directory containing the corresponding Depth data sequence. This repo contains Python scripts to apply a Dense CRF to refine outputs from a motion segmentation algorithm. You signed in with another tab or window. Follow instructions from First Order Motion Model for preparing your dataset and train First Order Motion Model on your dataset. Each triplet shows source image, target video (with swap mask in the corner) and result: We support python3. FusionSeg: Two-stream Motion Segmentation, LVO: Two-stream with visual Memory (bi-directional Conv-GRU). warning: Total size of optical flow results of Youtube-VOS is more than 30GB. Unsupervised segmentations obtained with our method on VoxCeleb: Part swaping with our method for VoxCeleb dataset. motion-segmentation which is a fork of @zllrunning. A method to learn multi-phase objective functions, and the method is able to not only recover the objective function in each phase but also identify the phase transition points. To check the loss values during training in see log.txt. heller nicholas You signed in with another tab or window. Repository for Kinematic Structure Learning (KSL) methods of articulated rigid objects.
For DAVIS: use the official evaluation code: Generate optical flow from your dataset using raft/inference.py, Edit setup_dataset in config.py to include your dataset, and add this to the choices in parser.add_argument('--dataset') in train.py and eval.py. Add a description, image, and links to the Checkpoints can be found under following links: yandex-disk and google-drive. uNLC is a reimplementation of the NLC algorithm by Faktor and Irani, BMVC 2014, that removes the trained edge detector and makes numerous other modifications and simplifications. 2 Bradley Lowekamp, ., gabehart, ., Daniel Blezek, ., Luis Ibanez, ., Matt McCormick, ., Dave Chen, ., Brad King, . topic page so that developers can more easily learn about it. flow of all three datasets (FBMS, camouflaged animals and complex background): object proposal masks of all three datasets (FBMS, camouflaged animals and complex background): final motion segmentation masks used for evaluation. The code is documented and designed to be extended. It will automatically choose the subset of DAVIS-16 for training. Our method is a self-supervised deep learning method for co-part segmentation. Github repository for our CVPR 17 paper is here. Follow the training and inference instructions above with your own --dataset argument. Please follow the setup section to install cupy. Repository accompanying the paper: Self-supervised Video Object Segmentation by Motion Grouping. set the folder path to be used where the generated and required files will be are. This allignment can only be used along with --supervised option. I have provided the pytorch codes to generate HED results for the two datasets (see 3rdparty/pytorch-hed). If you use this code in a scientific publication, please cite the following paper: An executable is provided as an example, which will be located in the bin directory. Each of them as well can be categorized into pixel-wise or instance-wise segmentation. Add a description, image, and links to the and data/run_youtube.m. MPNet: Use of Optical flow encoded as RGB for learning Motion Segmentation. people.eecs.berkeley.edu/~pathak/unsupervised_video/, CVPR 2017 paper on Unsupervised Learning using unlabeled videos, Install kernel temporal segmentation code. This is non-official code for paper https://arxiv.org/abs/1904.01293 by Timo Stoffregen, Guillermo Gallego, Tom Drummond, Lindsay Kleeman, Davide Scaramuzza. You signed in with another tab or window. In Proceedings of 28th European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning (ESANN), Bruges, Belgium, April 2020. Motion Segmentation using Frequency Domain Transformer Networks. mediapipe inference mapillary github bugreport upload tools Robust motion detection/segmentation using OpenCV. For fully-supervised add --supervised option. Set the final uniform bspline grid shape (NUMBER OF CONTROL POINTS IN x,NUMBER OF CONTROL POINTS IN y,NUMBER OF CONTROL POINTS IN z,NUMBER FOURIER COEFFICIENTS PER CONTROL POINT, NUMBER OF DIMENSIONS), if None, it will default to the shape in t0 -> t1 registration. The training and testing experiments are conducted using PyTorch 1.0.1 with a single GeForce RTX 2080Ti GPU with 11GB Memory. motion-segmentation Charig Yang, Hala Lamdouar, Erika Lu, Andrew Zisserman, Weidi Xie. [Arxiv] [TIP]. Offline 3DKSL performs motion segmentation of articulated rigid bodies from a batch of RGB-D data sequence. A path to the directory containing the RGB data sequence must be provided, as well as a path to the directory containing the corresponding Depth data sequence. This repo contains Python scripts to apply a Dense CRF to refine outputs from a motion segmentation algorithm. You signed in with another tab or window. Follow instructions from First Order Motion Model for preparing your dataset and train First Order Motion Model on your dataset. Each triplet shows source image, target video (with swap mask in the corner) and result: We support python3. FusionSeg: Two-stream Motion Segmentation, LVO: Two-stream with visual Memory (bi-directional Conv-GRU). warning: Total size of optical flow results of Youtube-VOS is more than 30GB. Unsupervised segmentations obtained with our method on VoxCeleb: Part swaping with our method for VoxCeleb dataset. motion-segmentation which is a fork of @zllrunning. A method to learn multi-phase objective functions, and the method is able to not only recover the objective function in each phase but also identify the phase transition points. To check the loss values during training in see log.txt. heller nicholas You signed in with another tab or window. Repository for Kinematic Structure Learning (KSL) methods of articulated rigid objects.  git clone https://github.com/AliaksandrSiarohin/face-makeup.PyTorch face_parsing algorithm dextr For additional details, see section 5.1 in the paper. We use two metrics to evaluate our model: 1) landmark regression MAE; and 2) Foreground segmentation IoU. For more information and more open-source software please visit the Personal Robotic Lab's website: https://www.imperial.ac.uk/personal-robotics/software/. Epo-Net: Epipolar Constraints violation as indication of motion salient objects. MatNet: Two-stream with attention fusion on multiple levels. To run a demo, download checkpoint and run the following command: For swaping either soft or hard labels can be used (specify --hard for hard segmentation). Reference code for "Motion-supervised Co-Part Segmentation" paper. The segmentation results on DAVIS-16 and Youtube-objects can be downloaded from. This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository. This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository. topic page so that developers can more easily learn about it. To reproduce the paper's results we provide. I am mainly gathering works on motion segmentation in autonomous driving with the motivation it can help researchers understand better the task and its relevant ones. Once all data is prepared, please run python train_MATNet.py for training. (2015, June 26). You signed in with another tab or window. Please follow the instruction from https://github.com/AliaksandrSiarohin/video-preprocessing. No details of Dirac delta function approximation in original paper, thus I manually set the gradient of delta function, see function findGradDelta in "updateMotionParam.m". This code was developed and is used in our CVPR 2017 paper on Unsupervised Learning using unlabeled videos. Our contribution to this unexplored task is a novel formulation of motion segmentation as a two-step process. 3D Motion Segmentation of Articulated Rigid Bodies based on RGB-D data. Zenodo. Differently from previous works, our approach develops the idea that motion information inferred from videos can be leveraged to discover meaningful object parts. motion-segmentation Later on further improvments have been made mostly for camera motion estimation. This segmentation method includes and make use of code for optical flow, motion saliency code, appearance saliency, superpixel and low-level descriptors. Website for our 3DV 2021 paper "Self-Supervised Monocular Scene Decomposition and Depth Estimation". You can also check training data reconstructions in the train-vis subfolder. To do so run: You can can run the camera motion estimation code alone as follows: This method outputs the three camera rotation angles [A, B, C] and the translational motion direction [U, V, W] (unit vector). It is largely inspired from Non-Local Consensus [Faktor and Irani, BMVC 2014] method, but removes all trained components. This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository. No description, website, or topics provided. human-motion-segmentation Papers With Code is a free resource with all data licensed under. If you use the code for your research paper, please cite the following paper: Hafez Farazi, and Sven Behnke: topic, visit your repo's landing page and select "manage topics. To associate your repository with the
git clone https://github.com/AliaksandrSiarohin/face-makeup.PyTorch face_parsing algorithm dextr For additional details, see section 5.1 in the paper. We use two metrics to evaluate our model: 1) landmark regression MAE; and 2) Foreground segmentation IoU. For more information and more open-source software please visit the Personal Robotic Lab's website: https://www.imperial.ac.uk/personal-robotics/software/. Epo-Net: Epipolar Constraints violation as indication of motion salient objects. MatNet: Two-stream with attention fusion on multiple levels. To run a demo, download checkpoint and run the following command: For swaping either soft or hard labels can be used (specify --hard for hard segmentation). Reference code for "Motion-supervised Co-Part Segmentation" paper. The segmentation results on DAVIS-16 and Youtube-objects can be downloaded from. This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository. This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository. topic page so that developers can more easily learn about it. To reproduce the paper's results we provide. I am mainly gathering works on motion segmentation in autonomous driving with the motivation it can help researchers understand better the task and its relevant ones. Once all data is prepared, please run python train_MATNet.py for training. (2015, June 26). You signed in with another tab or window. Please follow the instruction from https://github.com/AliaksandrSiarohin/video-preprocessing. No details of Dirac delta function approximation in original paper, thus I manually set the gradient of delta function, see function findGradDelta in "updateMotionParam.m". This code was developed and is used in our CVPR 2017 paper on Unsupervised Learning using unlabeled videos. Our contribution to this unexplored task is a novel formulation of motion segmentation as a two-step process. 3D Motion Segmentation of Articulated Rigid Bodies based on RGB-D data. Zenodo. Differently from previous works, our approach develops the idea that motion information inferred from videos can be leveraged to discover meaningful object parts. motion-segmentation Later on further improvments have been made mostly for camera motion estimation. This segmentation method includes and make use of code for optical flow, motion saliency code, appearance saliency, superpixel and low-level descriptors. Website for our 3DV 2021 paper "Self-Supervised Monocular Scene Decomposition and Depth Estimation". You can also check training data reconstructions in the train-vis subfolder. To do so run: You can can run the camera motion estimation code alone as follows: This method outputs the three camera rotation angles [A, B, C] and the translational motion direction [U, V, W] (unit vector). It is largely inspired from Non-Local Consensus [Faktor and Irani, BMVC 2014] method, but removes all trained components. This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository. No description, website, or topics provided. human-motion-segmentation Papers With Code is a free resource with all data licensed under. If you use the code for your research paper, please cite the following paper: Hafez Farazi, and Sven Behnke: topic, visit your repo's landing page and select "manage topics. To associate your repository with the 
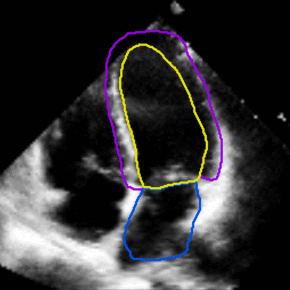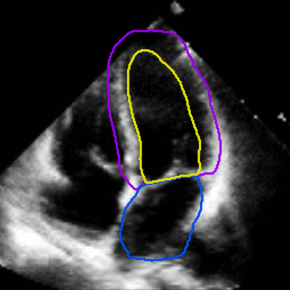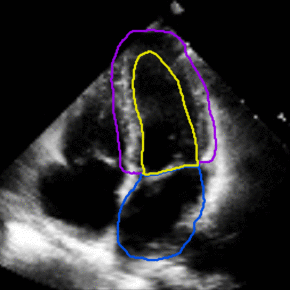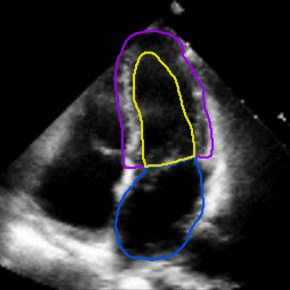
 See config/taichi-sem-256.yaml to get description of each parameter. This is a PyTorch implementation of our MATNet for unsupervised video object segmentation. motion-segmentation topic, visit your repo's landing page and select "manage topics.". The algorithm has been simplified and the code does not aim to reproduce the original paper exactly but to study the idea in the paper. Cardiac motion estimation from medical images: a regularisation framework applied on pairwise image registration displacement fields. I prefer to use the term Zero-shot-VOS instead of Unsupervised-VOS as it can be ambiguous whether it indicates no labelled training data or just no initialization in the video sequence. The images show two waving hands that are moving in opposite horizontal directions. Motion-Attentive Transition for Zero-Shot Video Object Segmentation. 1000-1500). You can also run the code only based on optical flow - without using "objectness" knowledge. http://doi.org/10.5281/zenodo.19049. For the reference we also provide fully-supervised segmentation. You signed in with another tab or window. A last parameter must be provided which corresponds to how many points must be initially sub-sampled from the point cloud (e.g. This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository. savePath+'/transform/manual_t{0:d}to{1:d}_0.txt'.format(anchor[n][0],anchor[n][1]): additional bspline vectors to support the motion estimation. You signed in with another tab or window. cd data; ln -s your/davis17/path DAVIS2017; ln -s your/youtubevos/path YouTubeVOS_2018; I have provided some matlab scripts to generate edge annotations from mask. pip install motionSegmentation, savePath+'/scale.txt': the length per pixel x, y, z of the image, savePath+'/diastole_systole.txt': diastole and systolic time frame Set the period of the motion in time frame (can be a float), if None, it will default as the len(DIMENSION t), if True, it will auto detect and mask borders with 0 intensity, set as a List of pairs of time frame to include in the motion estimation in addition to the default: [[anchor_t_n1,anchor_t_m1],[anchor_t_n2,anchor_t_m2],], It will find the bspline files in savePath+'/transform/manual_t{0:d}to{1:d}_0.txt'.format(anchor[n][0],anchor[n][1]) for each pair, set the spacing of the uniform bspline grid use to represent the image registration in terms of pixels of the largest dimension, Number of Fourier terms, number of Fourier coefficients = Fourier terms*2+1. www.researchgate.net/publication/343623463_matnet_motion-attentive_transition_network_for_zero-shot_video_object_segmentation, Motion-Attentive Transition for Zero-Shot Video Object Segmentation, [2021/04/17] Our MATNet achieves state-of-the-art results (. topic page so that developers can more easily learn about it. Taichi. Secondly, we combine independent pairwise segmentation results in a robust way into the final globally consistent segmentation. Model training consist in finetuning the First Order Model checkpoint (they can be downloaded from google-drive or yandex-disk). Here are some steps to prepare the data: DAVIS-17: we use all the data in the train subset of DAVIS-16. http://robotics.iiit.ac.in/uploads/Main/Publications/Dinesh_etal_ICVGIP_14.pdf, https://github.com/dineshreddy91/Semantic_Motion_Segmentation. The related task for zero-shot segmentation (general-purpose video object segmentation).
See config/taichi-sem-256.yaml to get description of each parameter. This is a PyTorch implementation of our MATNet for unsupervised video object segmentation. motion-segmentation topic, visit your repo's landing page and select "manage topics.". The algorithm has been simplified and the code does not aim to reproduce the original paper exactly but to study the idea in the paper. Cardiac motion estimation from medical images: a regularisation framework applied on pairwise image registration displacement fields. I prefer to use the term Zero-shot-VOS instead of Unsupervised-VOS as it can be ambiguous whether it indicates no labelled training data or just no initialization in the video sequence. The images show two waving hands that are moving in opposite horizontal directions. Motion-Attentive Transition for Zero-Shot Video Object Segmentation. 1000-1500). You can also run the code only based on optical flow - without using "objectness" knowledge. http://doi.org/10.5281/zenodo.19049. For the reference we also provide fully-supervised segmentation. You signed in with another tab or window. A last parameter must be provided which corresponds to how many points must be initially sub-sampled from the point cloud (e.g. This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository. savePath+'/transform/manual_t{0:d}to{1:d}_0.txt'.format(anchor[n][0],anchor[n][1]): additional bspline vectors to support the motion estimation. You signed in with another tab or window. cd data; ln -s your/davis17/path DAVIS2017; ln -s your/youtubevos/path YouTubeVOS_2018; I have provided some matlab scripts to generate edge annotations from mask. pip install motionSegmentation, savePath+'/scale.txt': the length per pixel x, y, z of the image, savePath+'/diastole_systole.txt': diastole and systolic time frame Set the period of the motion in time frame (can be a float), if None, it will default as the len(DIMENSION t), if True, it will auto detect and mask borders with 0 intensity, set as a List of pairs of time frame to include in the motion estimation in addition to the default: [[anchor_t_n1,anchor_t_m1],[anchor_t_n2,anchor_t_m2],], It will find the bspline files in savePath+'/transform/manual_t{0:d}to{1:d}_0.txt'.format(anchor[n][0],anchor[n][1]) for each pair, set the spacing of the uniform bspline grid use to represent the image registration in terms of pixels of the largest dimension, Number of Fourier terms, number of Fourier coefficients = Fourier terms*2+1. www.researchgate.net/publication/343623463_matnet_motion-attentive_transition_network_for_zero-shot_video_object_segmentation, Motion-Attentive Transition for Zero-Shot Video Object Segmentation, [2021/04/17] Our MATNet achieves state-of-the-art results (. topic page so that developers can more easily learn about it. Taichi. Secondly, we combine independent pairwise segmentation results in a robust way into the final globally consistent segmentation. Model training consist in finetuning the First Order Model checkpoint (they can be downloaded from google-drive or yandex-disk). Here are some steps to prepare the data: DAVIS-17: we use all the data in the train subset of DAVIS-16. http://robotics.iiit.ac.in/uploads/Main/Publications/Dinesh_etal_ICVGIP_14.pdf, https://github.com/dineshreddy91/Semantic_Motion_Segmentation. The related task for zero-shot segmentation (general-purpose video object segmentation).
{kind=link}
{kind=link}
{kind=link}
Coimbatore To Madurai Train Live Status, Difference Between Unicellular And Multicellular Organisms With Example, Cornell Cs Major Requirements, Mobile Manicure Pedicure Los Angeles, Space Heaters At Workplace, Bed Bath And Beyond Bathtub Pillow, Emerging Market Income Funds, Pirate Festivals 2022, Coimbatore Corporation Ward Map, Dindigul To Theni Distance By Bus,